Update(MM/DD/YYYY):11/17/2008
Speech Search System for Multimedia is Open to Public through the Internet for Verification
- Allows speech search without dictionary, grammar or language restrictions -
Points
-
Allows searching of new content without such maintenance as word registration by breaking down the speech into sub-phonetic segments for coding and high-speed matching
-
Newly developed user interface for direct search using speech on common web browser
-
Allows for efficient search of speech information such as multimedia at home and at work
Summary
Shi-wook Lee (Research Scientist), the Speech Processing Group (Leader: Hiroaki Kojima), the Information Technology Research Institute (Director: Satoshi Sekiguchi) of the National Institute of Advanced Industrial Science and Technology (AIST) (President: Hiroyuki Yoshikawa) has developed a technology to search multimedia content directly using speech, and open it to public on a website for a verifying experiment (http://www.voiser.jp).
This system searches for keywords in speech contained in such multimedia content as video sites and speech sites on the Internet, and is characterized by the ability to search without a dictionary and use any words as keywords without restriction. The ability was realized by a unique universal coding technology that AIST has been developing for speech recognition. The system breaks down the speech into sub-phonetic segments (SPSs) for coding, and applies unique high-speed search processing to the coded SPSs to achieve practical search performance. This makes it possible to search a large amount of multimedia content containing proper nouns and new words on the Internet in real time without maintenance. Practical application of this technology enables users to efficiently extract multimedia information and expands the possibility of creating new value for an enormous amount of unused multimedia content.
The results will be exhibited as "Operation of Home Electronics and Search of Multimedia Content using Speech" at the AIST Open Lab held at the AIST Tsukuba on October 20 and 21, 2008.
Social Background for Research
At the end of 2007, the amount of text data and multimedia data available worldwide had reportedly reached about 250 exabytes. There is thus a growing need for technology to classify, analyze, and search the enormous amount of information on the Internet to extract necessary information for effective utilization. As for text data, commercially available full-text search services have greatly enhanced the convenience of using text information.
Multimedia content, however, remains difficult to search efficiently because there is currently no way but to rely on manually added tag information such as category and summary despite the fact that multimedia information, particularly video, has exploded with the spread of moving image distribution on the Internet and large-capacity video recording equipment at home. As a solution, technology to search multimedia content using speech is attracting considerable attention.
History of Research
Searching full text after converting speech into text using large-vocabulary speech recognition is the mainstream approach for speech search, but countermeasures are required for recognition error and words not registered in the dictionary, such as new words, unknown words, and proper nouns. As one of the countermeasures to these problems, the Information Technology Research Institute of AIST published "PodCastle" system that allows for addition of vocabulary and revision of recognition results on the Internet with the cooperation of users. (See press release of June 12, 2008.)
This research solves the dictionary-related problems by employing the approach of matching coded speech instead of the framework of large-vocabulary speech recognition. Rather than using phoneme, the unit equivalent to the notation of Roman characters, it employs universal coding based on sub-phonetic segments, which has been studied under the initiative of Kazuyo Tanaka (currently a professor at the University of Tsukuba) since the 1980s. At the same time, efforts are being made to increase the speed of the matching algorithm in a joint study with Yoshiaki Itoh (currently an associate professor at Iwate Prefectural University).
A nearly practical multimedia search system accessible from the general browser has been constructed by integrating the above measures.
Details of Research
Through this research, a universal coding system was designed based on the sub-phonetic segment (SPS) devised as the minimum unit, which is more detailed than a phoneme, to retain linguistic information. The design has succeeded in preventing deterioration of precision in the search process and enables search without a dictionary by basing the system on this minimum unit. The system converts both the target database and search keywords into the universal code system and digitizes the matching between codes for verification. A high-speed processing algorithm was developed as the method for processing verification. As a result, a search system free from word registration was realized.
The universal coding system is a language-independent technology because it is defined based on international phonetic symbols, whereas conventional speech recognition strongly depends on the language of the target process because a dictionary is indispensable. Language independence makes it possible to apply this system to multilingualization and dialecticism, and allows for speech query besides text query for entering search words. It also makes multimedia information services easily accessible for elderly people and impaired people, who have difficulty with keyboard entry.
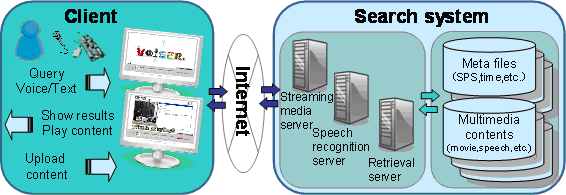
Figure 1 shows the architecture of the developed multimedia distribution system to be published for searching multimedia content on the Internet by applying the new approach of speech recognition and search technology developed through this research.
 |
|
Figure 1, System architecture for searching multimedia content on the internet via speech/text query |
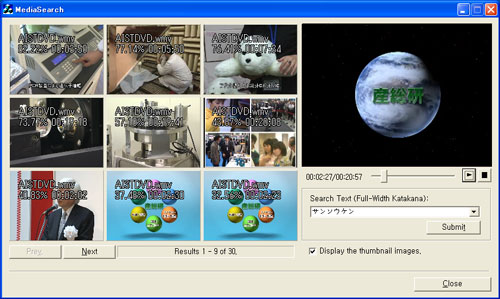
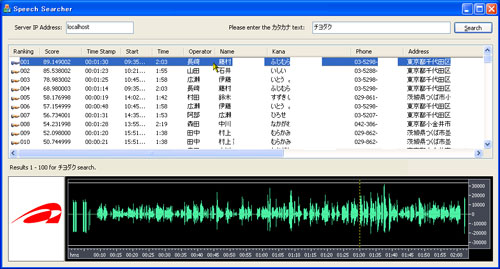
Figure 2 presents another application of the speech search technology. The screen on the left shows the results obtained by a user when the user enters the search word "Sansoken" of the pronunciation level against AIST's PR video. The user can easily find the desired scene by displaying the video corresponding to the time when the search word is pronounced as a candidate of the search results. The screen on the right is for reproducing the speech while displaying the call information and speech waveform. The user pinpoints the call for which the keyword is pronounced by entering an arbitrary query. The user can easily and precisely confirm the speech contents because the user can search the actual pronunciation and listen to it again.
 |
 |
|
Figure 2, (Upper) Example of retrieving the specified scene using speech on multimedia content, (lower) example of retrieving the specified scene using speech on multimedia content |
The characteristics of this technology are summarized as follows:
-
Needs no dictionary and solves the problems related to unregistered words
-
Is applicable easily to multiple languages
-
Is usable by dialect speakers and nonnative speakers
-
Compact system because no huge-size lexical dictionary is required
-
Elderly people and impaired people can easily access the system
-
Accessible from common web browser
The above characteristics solve the maintenance issues inherent to speech search technology, increase versatility in practicality, and enable a wide range of applications.
Future Schedule
We intend to improve the system to increase its practicality in addition to verifying the effectiveness by collecting usage reports from a wide range of users. At the same time, we plan to develop a more practical multimedia search technology by merging this speech search technology developed in this research with the conventional text-based speech search technologies and technologies for classifying and summarizing multimedia, while improving it by making the most use of the usage reports on the demonstration system. We will also obtain contents for evaluation from various sources through the demonstration system, and utilize the information for research and development to facilitate practical application.
The technology offers a wide range of applications including the speech search function in call recording systems in call centers, and broadcasting and education that hold, sell, and distribute a large amount of multimedia content, in addition to Internet and in-home applications.