自然言語処理とは?
自然言語処理とは?

2023/06/21

自然言語処理
とは?
―研究者もおどろく急成長! 自然言語でAIどうしがつながる未来―
科学の目でみる、
社会が注目する本当の理由

自然言語処理とは?
今話題の「ChatGPT」を実現した技術が自然言語処理です。質問への回答、文章の要約や翻訳、ソフトウエアのプログラミングなど、言語に関わるさまざまな作業をコンピュータで実行できるようになります。高機能化のカギは、深層学習(ディープラーニング)の進化にあります。最先端の自然言語処理システムでは、想像を絶するほど大量の文章を使い、パラメータ(数式の係数)が数千億に達するほどの大規模な「言語モデル」を学習させて使っています。言語処理は、静止画や動画、音声、またロボットの動作生成といった異なる種類のデータ処理と組み合わせることで幅広い活用の可能性があり、私たちの仕事や生活を大きく変えるかもしれません。
2022年11月に登場した、OpenAIの対話型AIサービス「ChatGPT」は、入力した質問に対して専門家と見分けがつかないような回答を返して世界中を驚かせました。この成果をもたらした自然言語処理技術の急激な進歩は、最先端の研究者の予想を超えるほどです。一方で、機能が高度になり過ぎてしまい、人の仕事を奪うどころか、いずれは人類を危機に陥れるといった恐ろしげな話も横行しています。果たしてどこまでが本当なのでしょうか。自然言語処理技術の原理や最新動向、産総研での人工知能研究について、人工知能研究センター 知識情報研究チーム 高村大也研究チーム長に聞きました。
自然言語処理とは
ChatGPTだけで、言語に関わるさまざまなタスクができるように
自然言語処理とは、人が書いたり話したりする言葉をコンピュータで処理する技術です。人工知能(AI)の研究分野で中核を成す要素技術の一つといえます。
自然言語処理技術は「言語理解」と「言語生成」に大きく二つに分けることができます。「言語理解」は人が書いた文章に対してなんらかの処理をする技術で、メールの自動分類、ウェブ検索などが典型的な応用になります。「言語生成」は、コンピュータに文章を生成させる技術で、文章の要約や機械翻訳などを含みます。
これまでは個別の用途ごとに技術開発が進んできましたが、ChatGPTをはじめとする最近のシステムがこの常識を変えました。高度な「言語理解」と「言語生成」が必要な質問応答もできるようになり、さまざまな作業(タスク)を一つのシステムでこなせるようになっています。
実はChatGPTが世間を騒がせる前から、自然言語処理の研究者の間では技術の急速な進歩に驚きの声が上がっていました。2018年にGoogleが発表した「BERT(バート)」というシステムでは、開発者が少し手を加えるだけでさまざまなタスクに使えるようになりました。それだけでも驚きでしたが、ChatGPTの前身である「GPT-2」や「GPT-3」では、システム自体を変更せずとも、人がシステムにあわせて入力を工夫するだけで多様なタスクの実行が可能になったのです。さらに、ChatGPTは人との対話能力が強化され、人間が人間に頼むような言葉で指示をするだけで、さまざまなタスクができるようになりました。
研究を加速した深層学習技術
急速な進歩の背景には、深層学習技術の発展があります。深層学習を用いた自然言語処理には、あらかじめ用意した膨大な文章を使って、「言語モデル」と呼ばれるシステムを学習させる方法があります。言語モデルに文章を途中まで入力して、次に来る単語が何かを予測するように学習させると、言語モデルは連続しやすい単語のパターンを次第に覚えていきます。そして、学習用の文章を大量に与えるほど、文章の組み立て方がうまくなっていくのです。
言語モデルというと何やらえたいが知れませんが、その実体は簡単な計算式を大量に組み合わせた超巨大な数式といえます。この数式には膨大な係数(パラメータ)を含んでおり、あとに続く単語の予測がうまくいくようにパラメータを調整することを、学習または訓練(トレーニング)と呼び、コンピュータで自動的に実行できます。学習後の言語モデルに質問などを入力すると、それに続く単語を次々に予測することで、長文の回答が出来上がってくるわけです。
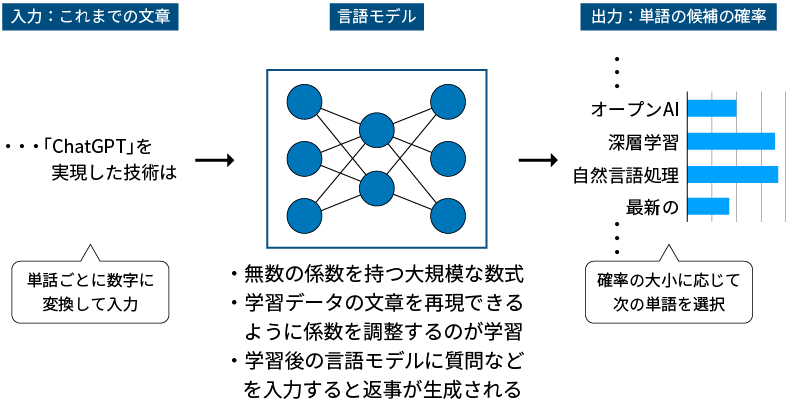
現在の高性能な言語モデルは大規模言語モデル(LLM : Large Language Models)といわれ、パラメータの数は一千億から数千億以上、学習に使う単語の量も数千億以上に達するとされます。LLMが人間に匹敵するほどの高度な能力を持つようになったのは、大規模化のおかげといわれています。ChatGPTもLLMをもとに、会話の能力を高める追加の学習を施して開発されたと考えられています。
なぜ高度な処理が可能になったのか
大規模言語モデルが高度な能力を獲得できた理由は、いくつか考えられます。
まず、システム自体が学習によって作られるようになりました。以前の自然言語処理技術では、各言語の文法や人が考えたルールに基づいて、個別のタスクを実行するシステムを作ってきました。その後、比較的小規模な深層学習などを適用しながら自然言語処理技術を発展させてきました。
これに対して、言語モデルの性能のカギである膨大なパラメータは、すべて学習によって決まります。その結果、言語モデルの内部では、単語や文章の構造などの情報が、さまざまなタスクを実行しやすい形式で保存されていると考えられています。人が考える代わりにデータに決めさせてみたら、実用に適した表現形式が見つかったというわけです。ただし、この表現は人がすぐには理解できないような複雑な形態になっていると考えられています。
ほかにも、学習後のパラメータには学習に使った大量の文章が持つ知識が、記憶されていることも性能向上に貢献しています。ChatGPTが質問に対してきちんと答えを返せるのは、質問のあとに続く確率が高い単語の連なりとして、大量の文章から答えを構成する情報を学んでいるからです。
大規模言語モデルの大きな謎は、明示的に学習させていないタスクも実行できることです。従来の自然言語処理技術や小規模な言語モデルで異なるタスクに対応するには、別のシステムを作ったり、タスクごとのデータを改めて用意して再学習させたりする必要がありました。
これに対して、例えばChatGPTは、「次の文章の文法の間違いを指摘してください」「次の意見は肯定的、否定的、中立のどれですか」と指示するだけで、こうしたタスクを解くことができます。指示の中に実行の条件や結果の例を含めることで、まったく新しいタスクも扱えます。言語モデルへの指示は「プロンプト」と呼ばれており、どのようなプロンプトを入力すると、どのようなタスクを精度よく実行できるのかが、盛んに調べられています。
「言語モデルが大規模になると、新しい機能が創発する」は本当か
ChatGPTが明示的に学習させていないタスクが実行できる理由の説明の一つは「言語モデルが大規模になると、新しい機能が創発する」という見解です。ただし、これには異論もあります。例えば、大規模言語モデルの学習にはインターネットなどから集めた膨大な文章が使われているため、新しいタスクのテストをしているつもりが、実はそのテスト用のデータがすでに学習用データの中に紛れ込んでいたのではないかとの指摘です。つまり、大規模言語モデルは、意図せずして「カンニング」をしているのかもしれません。
これらの点を含めて、言語モデルの動作にはわからないことがまだたくさんあります。そもそも、文中であとに続く単語を確率的に予測するだけで、どうして人が書いたような文章を生成できるのかを具体的に説明できる理論がまだないのです。
産総研では、言語モデルの内部を詳細に調べて、この点を少しでも明らかにしたいと考えています。言語モデルは階層的な構造を持っており、どこかの階層で従来の「構文解析(文法に従って単語の関係を整理する)」に相当する処理をしているのかもしれません。
なお、言語モデルは人工知能の分野で「生成AI(generative model)」と呼ばれる技術の一つです。生成AIには言葉で指示すると画像を生成するAIなどもあり、「Midjourney(ミッドジャーニー)」「Stable Diffusion(ステーブル・ディフュージョン)」といったサービスが、やはり世間の注目を集めています。実は画像の生成AIも、言語モデルと同様に確率的な発想をもとにしています。非常に単純化していえば、例えば顔画像の生成を考えると、目や口、鼻といった共通の特徴がある中で、その形や配置、色などが確率的に変動することで、さまざまな画像が出来上がるイメージです。(「ジェネレーティブAIとは?―『次世代のAI』に期待されていることー」)
自然言語処理とAIの未来
私たちの仕事はAIに奪われる?
ChatGPTが示したように、現在の自然言語処理技術を使うことで、文章の作成や会話を利用するさまざまな仕事を、コンピュータに任せることが可能になってきました。ただし、現状の技術には大きな制約があり、完全に人手が不要になる業務はまだ少ないといわれています。
この制約とは、人の指示に対してシステムが出力する情報が必ずしも正しくないことです。ChatGPTの回答に、しばしば誤りが含まれていることはよく知られています。理由は前述した通り、生成される文章はあくまでも学習した確率に従った結果であって、内容の正しさを確かめたものではないからです。文章がもっともらしく見えても、中身が正確とは限らないわけです。
このため、現状の技術を文章の作成に活用する場合には、内容の正しさを人が確認することが必須だといえます。情報の正確性を問わない用途であれば、人手を介さずに使うことも可能ですが、現時点でその範囲は限定的だと考えられます。
言語モデルの出力をより正確にする技術は進歩を続けているものの、間違いを完全にゼロにするのは難しいでしょう。その分、人の出番はなくならないともいえます。ただし、人間も間違いを犯すので、言語モデルの正確さが人と同等になれば話が変わるかもしれません。自然言語処理技術の高度化に伴い、情報の正しさを重視しない用途から順番に、作業が自動化されていく可能性があります。一方で、自動的にAIが生成した文章を見つけたり、内容の事実確認(ファクトチェック)をしたりする技術の研究も進んでいます。
自然言語がAI同士をつなぐ
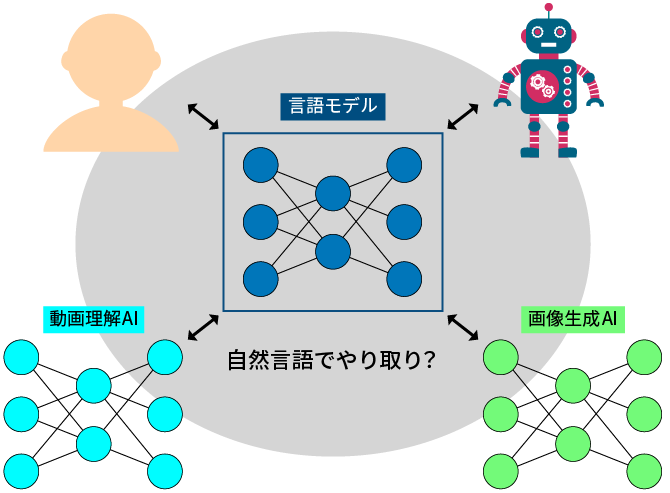
自然言語処理技術が今後向かう方向の一つは、言語処理を静止画や動画、3次元形状や音声といった異なる種類のデータ処理と組み合わせていくことです。これは「マルチモーダル化」などと呼ばれています。すでに、画像生成AIに望みのイラストを描かせるための指示(プロンプト)をChatGPTで作成するといった連携が始まっています。
研究段階では、ロボットの動作生成に言語モデルを利用する事例もあります。ロボットが置かれた状況を言語モデルに伝えると、次にすべき行動を言語モデルが推論するというものです。実際に適切な行動の生成が可能なようです。
マルチモーダル化は、それぞれのデータ処理を得意とするシステム同士が連携することで進んでいくと考えられています。面白いことに、システムの間で情報をやり取りする標準的な手段が、自然言語になっていく可能性もあります。AIへの指示(プロンプト)を介したやり取りはもちろん、ChatGPTの機能を拡張する「プラグイン」の仕組みでは、拡張用のソフトウエアの使い方を自然言語で記述してChatGPTに伝える形式をとっています。いずれは人とAIの間だけでなく、AIとAIが自然言語を介して対話する時代が訪れるのかもしれません。
もう一つの発展の方向性は、「パーソナル化」です。チャットの内容をはじめ、多種多様な個人の行動を継続的に記憶した言語モデルが、一人ひとりにカスタマイズしたサービスを提供する可能性があります。実際にマイクロソフトは、大規模言語モデルとオフィスソフトを連携させるツール「Copilot(コパイロット)」で、ユーザーごとのメールやチャット、文書や会議などのデータを活用することを明らかにしています。
この流れでいくと、ユーザーのプライバシーの保護が大きな課題になりそうです。すべてのデータをクラウドに保存する代わりに、プライベートな情報はスマホなどユーザーの手元のツールで管理し、一般的な知識を提供するクラウド上の言語モデルと連携する形になるかもしれません。
大規模言語モデル自体の機能も今以上に強化され、より多くのタスクで、よりよい結果を出せるようになっていきます。ここで重要なのは、最先端の技術を盛り込んだ大規模言語モデルを、日本も独自に開発する必要があることです。大規模言語モデルの内部でなにがおこっているのかを詳細に調べて研究開発を発展させるためにも、オープンな環境で使えるモデルを早く整備する必要があります。世界中で進む開発競争に取り残されないよう、これまで培ってきた最先端の自然言語処理技術を持ち寄って、他の研究機関や大学と連携し日本国内における大規模言語モデルの開発に貢献していきたいと考えています。