早大の良質・大量のデータと産総研の解析技術で医科学分野のイノベーションを目指す
早大の良質・大量のデータと産総研の解析技術で医科学分野のイノベーションを目指す

2017/03/31
早大の良質・大量のデータと産総研の解析技術で医科学分野のイノベーションを目指す生体システムビッグデータ解析オープンイノベーションラボラトリ

 ❶ 早大の良質・大量のデータと、産総研の幅広い解析技術を融合
❶ 早大の良質・大量のデータと、産総研の幅広い解析技術を融合
❷ バイオ系と情報系がともに、テーマ設定の段階から取り組む。
❸ 今必要な技術とともに、将来を見据えた挑戦的な研究も行う。
産総研は、大学の基礎研究と産総研の目的基礎研究を融合し、産業界へ橋渡ししていくことを目指して、大学のキャンパス内に連携研究拠点「オープンイノベーションラボラトリ(OIL)」の設置を進めている。 2016年7月には、早稲田大学のキャンパス内に産学官連携研究拠点「産総研・早大 生体システムビッグデータ解析オープンイノベーションラボラトリ(CBBD-OIL)」を開設した。具体的な研究内容と目指している成果、今後の展開などを中核メンバーに聞いた。
 仕切りのない大部屋で、視線が合わないようにデスクなどの配置が工夫された研究室。独立感をもって各自が自分の研究に集中できる一方、何かあればすぐに他の人に相談できる。
仕切りのない大部屋で、視線が合わないようにデスクなどの配置が工夫された研究室。独立感をもって各自が自分の研究に集中できる一方、何かあればすぐに他の人に相談できる。
OIL設立の機が熟した
――早稲田大学内にOILを設置することになった経緯を、推進役の中村さんからお聞かせください。
中村(産総研) CBBD-OILは、私立大学に設立する初めてのOILです。早稲田大学はバイオ分野で著名な研究者が多数いらっしゃる大学であり、海洋生物のメタゲノムデータをはじめ、良質なデータをたくさん保有しています。また、早稲田大学、産総研はともに高度な生命情報の解析技術をもっています。これらの研究データと技術を融合させることで、世界に冠たる研究ができることを期待し、生体システムビッグデータ解析についてのOIL設立に至りました。
竹山(早稲田大学) 私は、さまざまな生物種の遺伝子解析に従事してきましたが、バイオ系の研究には、生命情報解析技術の習得はとても重要と考えており、私が所属する生命医科学科の授業にもそれを取り入れようと思っていました。学生の中には、所属がバイオ系でも、バイオ研究から出てくる情報を解析することに興味をもつ者もいます。以前から産総研の生命情報解析の研究者たちとは、そのような学生をどう育てればよいのかという話をし、教育だけでなく、ビッグデータ解析など、バイオインフォマティクス研究も一緒に進められればと考えていました。
世の中では次世代シークエンサー*1の登場とともに、今までにはない量の生命情報やビッグデータが生み出されています。しかしながら、特にバイオ系のビッグデータを解析できる人材の不足が指摘されていました。私の周りでも同様で、そのような状況を踏まえ、自分たちのニーズ、シーズを考え合わせると、今がまさに行動を起こす時期だったと思います。早稲田大学にはバイオ系から情報系までさまざまな学科に幅広く人材がいて、かつ解析対象となる価値の高いバイオデータが豊富にあります。産総研から提案されたOILの話は、生体システムビッグデータ解析の必要性とそれを推進する諸条件がそろったところに訪れたチャンスと言えるものでした。
バイオ系と情報系の融合でブレークスルーを実現したい
――CBBD-OILの全体的な構想は?
中村 早稲田大学の良質なデータや配列解析アルゴリズム技術と、産総研の解析技術を融合させ、ビッグデータの集積・解析拠点を構築します。具体的には、配列ビッグデータなどから役立つ知見を抽出する情報解析技術を開発すること、そして、それを用いて生命メカニズムを解明し、医薬品や健康食品開発に橋渡しすることを目的としています。
竹山 これまでの生命情報解析の研究では、バイオ系と情報系研究者との間で、目的意識の共有やコミュニケーションがスムーズにいかないことが多かったのですが、 CBBD-OILではその点のブレークスルーを実現し、成功事例にしたいと考えています。
油谷(産総研) そのためには、実験と情報解析の専門家双方の技術やレベルにふさわしい研究を、実施する必要があります。CBBD-OILでは研究テーマや方針について、初期の段階から、両者がともに取り組むことで、研究のゴールのイメージを共有できる体制を作っています。
浜田(早稲田大学) すでに非常に多くのバイオ系データがありますが、解析技術自体はまだ十分とは言えません。私が班長を務める配列解析アルゴリズム班は、最先端の情報技術や数学、物理などのさまざまな知識人を総動員し、不足している解析技術の開発に取り組んでいます。
富永(産総研) 観測精度も、データの意味や情報を抽出する解析技術も限られていた20年前と違い、近年では、実験精度が上がって誤差が少なくなると同時に、コストも下がり蓄積データも増えてきました。同様の状況が、ほかの多くの分野でも見られるようになったことで、ディープラーニングなどのビッグデータ解析分野が興り、さまざまな解析手法が新たに生まれつつあります。CBBD-OILは、サイエンス全体にいろいろなものがそろった、まさにこのタイミングで取り組むべきものだと言えます。
多彩な人材、多彩な研究が強み
――産総研と早稲田大学、それぞれの強みは?
油谷 一言でバイオインフォマティクスと言っても、大変幅広く、配列解析や立体構造解析、数値解析ではまったく分野が異なります。産総研はさまざまな分野のバイオインフォマティクス研究者を幅広く有している国内では稀有な組織であり、バイオインフォマティクス研究で対応できないことはほぼないと言えます。これが産総研の強みと言えます。そこから今回は早稲田大学の保有するデータに合う研究者を探し、バイオ系データ解析の基盤となるアルゴリズム開発の専門家や、富永さんや私のような実データ解析を行う事業化の出口に近い研究者も加わり、橋渡しを進めやすい体制をつくりました。
竹山 ゲノムの時代では、各分野の研究者がコラボレーションしないと研究の進展が難しい状況になっています。早稲田大学は現在、バイオ系の研究に力を入れており、メディカルや基礎研究の研究者が、学部を超えて集まっています。医学部・薬学部をもたないことによるニュートラルなイメージにより、企業を含めて人材や情報が集積しやすいという強みもあります。
CBBD-OILにはそのような広がりをつくるプラットフォームとして機能することを期待しています。
今の社会ニーズに応えながら将来を見据えた研究にも挑戦
――具体的にどのような研究を行っているのですか。
油谷 社会ニーズに応える研究を進めるのはもちろんですが、それだけでは不十分です。生命情報解析において将来の標準になる技術をつくっていかなければ、バイオインフォマティクスに未来はありません。そのため浜田さんの配列解析アルゴリズム班には、今すぐ役に立つというよりも、挑戦的な研究をお願いしています。一方で富永さんのシステムズバイオロジー班には、医薬・生物の企業や先生方と密接にかかわり、現在求められている応用研究を進めていただいています。
浜田 配列解析アルゴリズム班は配列をメインに、長期的な視点での技術開発に取り組んでいます。生物データはDNAやRNA、タンパク質も抽象化すると配列として見ることができ、現在、その配列データが大量に蓄積されています。それを効率よく処理して効果的な知見を見いだすための、新しい方法論やアルゴリズムをつくろうとしています。
具体的には、大量の文字列データを比較し、処理していく技術や、RNAの中でも最近見つかっている、タンパク質にはならない「ノンコーディングRNA*2」のもつ機能を情報学的に推定する手法を開発しています。最近は、腸内の大量のバクテリアのメタゲノムデータを機械学習の技術を応用して解析する方法も考案しました。
富永 私の関心は生物の仕組みを完全に解き明かすことより、生体がどんなときにどんな振る舞いをするのか、観測される挙動を数学的に記述する方向にあります。例えば、人の遺伝子の働き方を測定すると、約5万個の遺伝子の活性が数値の羅列として出てきて、それを見ただけでは意味が把握できません。そのため実際の解析時には遺伝子群や機能などのくくりで働き方を捉え、それらの働きと働きの間の関係を調べたりします。つまり、生命の分子機械としての仕組みそのものではなく、人が理解できる枠組みに抽象化して探っていくのです。
メンバーシップ登録で研究成果を企業に橋渡ししやすく
――企業との連携のあり方についてはどうでしょうか。
竹山 現在、CBBD-OILには主に製薬会社のほか、食品業界など人の健康にかかわる企業にも加わっていただいています。細胞生物学で分子の動きを知ることは、それを制御する方法の研究にもつながるため、私たちには疾病メカニズムのような大きな生命現象の解析が求められています。
浜田 近年、解析しつくされてしまったタンパク質に代わり、ノンコーディングRNAの機能を推定する技術ができれば、将来的にはこれをターゲットにした製薬ができると期待されています。
富永 私はもっぱら現在使える技術で解析していますが、先に話した抽象化のレベルはある程度は任意に選べます。共同研究先の企業などが理解したい深度は研究の目的や期間などによって異なるわけですが、それを考慮して抽象化し、生体の機能などの解析結果を、相手が解釈しやすい形にして渡せるということです。それにより企業は、例えば、この微生物をどう改造すればどのような機能をもたせられるか、どうすれば薬をつくれるようになるのかといった指針が立てやすくなります。
中村 OILは、基礎研究から橋渡しまで一気通貫で行っていく研究拠点です。今後、参加企業をさらに増やしていきたいと考えています。
油谷 例えば、企業でゲノムに関する部署を立ち上げても、ゲノム解析に詳しい人材が社内にいるとは限りませんし、ゲノム解析の先にある数値データを扱う場はなかなかありません。CBBD-OILでは実際に企業で測定された実データを使って解析できます。また、OILで開発された新規の解析技術やその研究成果を知ることも可能です。何より、最先端のバイオインフォマティクス技術を試すための指導や相談を受けることもできるのです。
竹山 そこから共同研究に展開していくことも可能ですので、ぜひ、多くの企業にメンバーシップ登録をしていただき、CBBD-OILにご参加いただきたいですね。
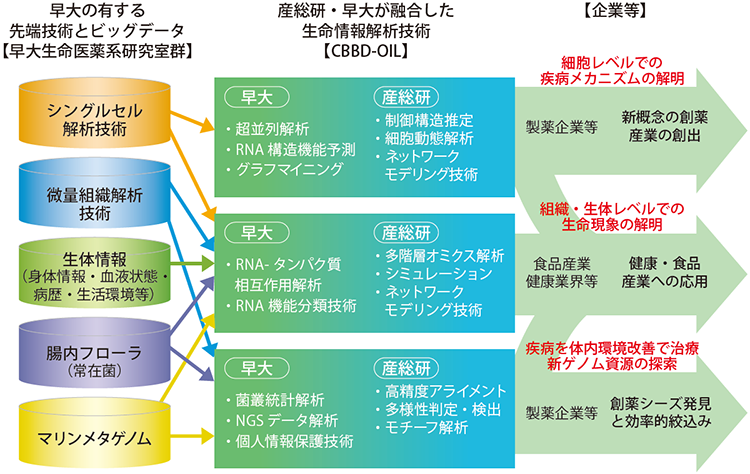 CBBD-OILの研究イメージ
CBBD-OILの研究イメージ
RA制度を活用して学生も参加
竹山 現在、CBBD-OILの研究室には12~13人の学生がいます。大学院生の産総研リサーチアシスタント(RA)が6名、技術研修生が4名、ほかに学部生も出入りしています。産総研のRA制度を用いて大学院生を雇用するのは、学生が研究に没頭できる環境を提供するためですが、それに対して学生は、研究面で成果を出すことが求められます。このようなマッチングはお互いに魅力的ですし、学生が研究テーマを広げることにも役立っています。現場で活躍する若い活力は私たちにもよい刺激になっています。
中村 RAは単なる研究アシスタントではなく、一人前の研究者として扱われます。自ら率先して研究を行い、優れた成果をあげられるこの環境に、多くの方々に参加してほしいです。
成果を上げ、国際的な認知度も高めたい
――今後のCBBD-OILの展開は?
竹山 OILは5年間の設置期限がありますが、発足から9カ月たった現在、参加者の間でビジョンを共有する下地ができ、多くのアイデアも出てきています。今後大きな成果を出すためのスタート地点とし、OIL終了後でも残したい研究拠点となるように成長できればと思います。
油谷 この研究拠点が5年後、10年後に自立運営するためには、企業との共同研究やOILへの参画も積極的に増やす必要があります。また、世界に点在しているバイオインフォマティクス研究所やバイオ系の研究所などとの国際連携も進め、国際的に認知される組織にしていきたいです。まずはよい論文を出し、企業との成果も積み重ねていくことが必要でしょう。
浜田 私はぜひ、将来、標準的に使われるCBBD-OIL発の情報解析技術を残したいです。
中村 大いに期待しています。外部資金も活用し、プロジェクト終了後には次のステップとして、得られた知見を企業における医薬品や健康食品開発に橋渡しを行うかたちで発展させていただきたいです。
*1: 遺伝子のDNA断片の塩基配列を読み出せる装置(Next Generation Sequencer:NGS)。これまでとは桁違いに多くの配列を、同時並列的に読みだすことができる。[参照元へ戻る]
*2: タンパク質に翻訳されず、独自に機能するRNA(non-coding RNA, ncRNA)。[参照元へ戻る]
生体システムビッグデータ解析オープンイノベーションラボラトリ
副ラボ長
油谷 幸代
Aburatani Sachiyo
早稲田大学
先進理工学部生命医科学科 教授
生体システムビッグデータ解析オープンイノベーションラボラトリ
ラボ長
竹山 春子
Takeyama Haruko
生体システムビッグデータ解析オープンイノベーションラボラトリ
システムズバイオロジー班
班長
富永 大介
Tominaga Daisuke
早稲田大学 先進理工学部電気・情報生命工学科 准教授
生体システムビッグデータ解析オープンイノベーションラボラトリ
配列解析アルゴリズム班
班長
浜田 道昭
Hamada Michiaki
企画本部
副本部長
中村 吉明
Nakamura Yoshiaki
産総研
企画本部
総合企画室
- 〒100-8921 東京都千代田区霞が関1-3-1
- pl-inquiry-ml*aist.go.jp
(*を@に変更して送信してください)
産総研・早大
生体システムビッグデータ解析オープンイノベーションラボラトリ(CBBD-OIL)