- 世界トップレベルの生成AIの基盤となる大規模言語モデル構築に研究所・大学の英知を結集して取り組む
- 第一歩として、国立情報学研究所が主宰するLLM-jpが日本語に特化したGPT-3級大規模言語モデル構築に着手
- 構築過程が明らかで安心して活用できる大規模言語モデルにより産業競争力強化や社会課題解決に貢献
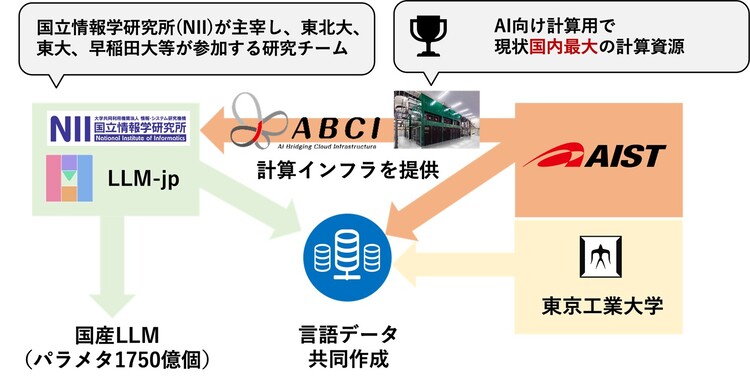
産総研、東京工業大学、LLM-jp(国立情報学研究所主宰)が協力して大規模言語モデルの研究開発
国立研究開発法人 産業技術総合研究所(以下「産総研」という)と、国立大学法人 東京工業大学(以下「東工大」という)、大学共同利用機関法人 情報・システム研究機構 国立情報学研究所(以下「NII」という)が主宰する勉強会LLM-jp(NII、東北大学、東京大学、早稲田大学などが参加するLLM研究開発チーム)は、生成AIの基盤となる世界トップレベルの大規模言語モデル(以下「LLM」という)の構築の開発を始めます。その第一歩として、LLM-jpが従来の国産LLMの10倍の規模を持つ1750億個のパラメタ数を持つLLMの構築に着手します。産総研はLLM構築に必要な計算資源であるAI橋渡しクラウド(以下「ABCI」という)を提供します。このほか、今後の開発に向けて東工大、LLM-jpと協力して開発に必要な言語データ作成を行います。
産総研、東工大、LLM-jpが持つLLM構築に関するデータ・アルゴリズム・計算資源活用の知見を持ち寄って研究開発を行うことで、日本の産業競争力強化や社会課題解決に資する成果を創出します。
AI技術は国の産業を支える柱の一つであり、労働力人口減少を補う効率的な仕事や、インターネットを通じて収集した大規模なデータの高度利活用に必須です。特に、言語を扱うAIの技術要素であるLLMの研究が進展しています。2022年には対話型AIであるChatGPTを、米企業OpenAIが公開しました。その流ちょうな対話文の生成能力は世界の人々を驚かせ、その豊富な知識源と用途の多さから、社会のあらゆる面での活用に期待が集まっています。しかし日本以外の企業・研究機関がクローズに研究開発を進めたLLMを活用するだけでは、LLM構築の過程がブラックボックス化してしまいます。そのためLLMを活用する際の権利侵害や情報漏えいなどの懸念を払拭できません。日本語に強いLLMの利活用のためには、構築の過程や用いるデータが明らかな、透明性の高い安心して利活用できる国産のLLM構築が必要です。
産総研はこれまで国立研究所や大学と連携してAI技術の研究開発を行ってきました。産総研とNIIの間では、2019年1月18日に産総研ABCIの活用や、AIに関わる研究協力などについての連携・協力協定を結んでいます。2023年にはABCIを用いたLLMの構築と、高品質かつ大規模な共有データセットの構築と管理に取り組むことについて、NIIと合意しました。これと並行して、産総研と東工大の間でもLLM構築の研究を進めてきました。
2023年9月にはNIIが代表機関、産総研、東工大、LLM-jpが参加機関としてABCIの第2回大規模言語モデル構築支援プログラムに応募し、採択されました。大規模言語モデル構築支援プログラムは、LLM構築の需要の高まりを背景として、ABCIの一定部分(Aノードと呼ばれる高性能な計算ノード)を最大60日間占有利用する機会を採択者に提供するもので、これによって大規模な計算資源が不可欠であるLLMの構築を推進できます。
世界トップレベルのLLMの構築に向けた第一歩として、LLM-jpがオープンでかつ日本語に強いLLMの構築に着手します。今回構築に着手するLLMの規模を表すパラメタ数は1750億個であり、OpenAI社が構築したLLMであるGPT-3と同等の規模です。産総研はLLMの構築に必要な計算資源としてABCIを提供します。このほか産総研と東工大は、LLM-jpとも協力しながら、LLM開発に必要な高品質かつ大規模な共有データセットの構築を行います。
今回の取り組みによって、日本で初めてのオープンに利用できるGPT-3級の日本語LLMの構築を目指します。これによって、構築の過程が明らかで透明性の高いLLMを用いた、マルチモーダルなデータを処理するAI技術の開発や、生成AIのロボット応用等に貢献します。またLLMの原理解明を進め、安心してLLMを利活用できる社会生活の実現につなげます。
今後とも産総研の持つ計算資源を活用しながら日本の英知を結集し、世界トップレベルの性能を持つLLMの構築を目標に研究開発を進めます。構築される国産LLMは、ABCI以外の計算資源も活用しながらモデルを完成させた上で、LLM-jpを通じて公開されます。
国立研究開発法人 産業技術総合研究所
情報・人間工学領域 研究企画室
〒305-8560 茨城県つくば市梅園1-1-1 中央事業所
E-mail:ith-liaison-ml*aist.go.jp(*を@に変更して使用してください。)