国立研究開発法人 産業技術総合研究所【理事長 中鉢 良治】(以下「産総研」という)は、平成28年7月29日に「産総研・早大 生体システムビッグデータ解析オープンイノベーションラボラトリ」(AIST-Waseda University Computational Bio Big-Data Open Innovation Laboratory; CBBD-OIL)を早稲田大学【総長 鎌田 薫】(以下「早大」という)と共同で設立しました。産総研のオープンイノベーションラボラトリ(OIL)は、産総研の第4期中長期計画(平成27年度~31年度)で掲げている「橋渡し」を推進していくための新たな研究組織の形態で、CBBD-OILがその第四号案件となります。また、CBBD-OILは私立大学と共同で設立する初めての組織となります。
現在、世界中でバイオ分野に情報技術を組み合わせることで、医薬分野をはじめ食品分野、化学品分野など多岐にわたる産業への応用が期待されています。最近では実験技術や機器の進歩が加速し、細胞単位、生体単位、集団単位と様々なレベルにおけるDNA、RNA、タンパク質といった様々な階層の生命データが指数関数的に増加しています。これらの増加しつづける生命データを有効に活用し、生命・医薬・健康分野の産業に役立つ知見を創出するためには、迅速に結果を示すことが可能な最適な情報解析技術を開発しなければ、世界的にも競争の激しい医薬品産業・健康産業においてアドバンテージを取ることはできません。
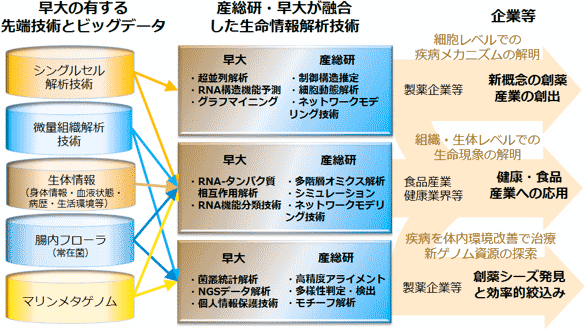
早大は、一細胞単位での挙動を解析するシングルセル解析において日本最大の技術を蓄積しており、人の腸内フローラ(細菌叢)や海洋生物(カイメン等)の共生・共在細菌群のゲノム全部を網羅的に測定するメタゲノム解析や、臓器等の生体組織から微量組織の連続的近接接取技術をシングルセル解析と組み合わせて、新しい生命データ創出に向けて世界をリードする基礎研究を行っています。また、超高速シーケンサーデータの情報解析技術やRNA配列からの機能・構造・相互作用予測に関する情報解析技術にも秀でています。一方、産総研は、大規模なゲノム配列を高速・高精度に比較し、遺伝子の持っている機能や疾病要因となっているゲノム上の変異等の知見を効率的に見出す情報解析技術や、疾患にともなって後天的に起こるゲノム修飾の異常を高精度に検出する情報解析技術を有し、これらの技術は世界有数のレベルにあります。また、システムズバイオロジー的なアプローチとして、遺伝子発現データ等の数値データから細胞内での遺伝子同士、タンパク質同士の相互作用を推定するネットワークモデリング情報解析技術の研究開発実績が多くあります。
今般、産総研と早大は新たな産総研の拠点(CBBD-OIL)を早大西早稲田キャンパスに設置し、早大が有する日本有数の生体システムビッグデータと、産総研・早大双方の情報解析シーズ技術を合わせ、生命現象のメカニズムをシステムとして理解し、疾病メカニズムの解明や究極の個別化医療への貢献を目指した研究開発を行います。さらに、産学官ネットワークの構築により、民間企業の参画による「橋渡し」につながる目的基礎研究の強化や、世界標準となる最先端の生命情報解析技術の研究開発を行います。
 |
|
産総研・早大 生体システムビッグデータ解析オープンイノベーションラボラトリ(CBBD-OIL) |
1)シングルセルデータからの疾病発症メカニズム解明
シングルセル解析において始まりつつあるゲノム配列とRNA情報の超並列解析の情報解析技術の開発にいち早く取り組みます。具体的には、ノンコーディングRNA(ncRNA)を含むRNA全般を研究対象の中心に据え、深層学習などの最先端の機械学習の手法を取り入れた、RNAと他の生体高分子の相互作用予測手法を開発します。シングルセルデータと疾病や健康を関連づけることで、疾病発症メカニズムを含む多様な生命現象の解明をめざします。
2)微量組織データからの組織・生体モデリング技術の開発
組織内での細胞個体の動態を解明するため、微量組織で測定されつつある組織切片全体の網羅的発現データ・位置情報データを統合的に解析する情報技術を開発します。具体的には微分方程式モデルや統計モデルによる定量的な遺伝子発現制御構造、細胞内因子量と3次元位置情報からの細胞内メカニズム推定技術を開発します。これにより、organs/tissue on a chip技術が発展する中、チップ上の組織解析データに適した世界標準となる情報解析手法を目指します。
3)腸内フローラデータからの疾病関連因子同定技術の開発
疾病と関連づけて測定されている腸内フローラデータと、疾病に関連する様々なタイプの生体情報を統合して解析する新しい情報解析技術を開発します。開発した手法によって、疾病に特異的な腸内の状態を明らかにし、疾病に寄与する因子の同定を行います。また、今後の個別化医療時代を見据え、個別に測定される膨大な量の個人の腸内フローラデータを効率的に圧縮する方法論や、個人情報を保護するために必要となるアルゴリズムの開発を行います。
4)マリンメタゲノムデータからの新しいゲノム資源発見のためのデータ整備と解析技術開発
最先端の数学・情報学の技術を活用したDNA/RNA配列情報解析の基盤技術を開発し、多種多様なゲノムデータが混在しているマリンメタゲノムデータから、創薬・医科学に有用な遺伝子情報を高速に獲得します。また、その基盤となる個体の多様性を表現可能な参照ゲノムの構築を行います。
平成28年7月29日(金)、早稲田大学西早稲田キャンパスに設立した「産総研・早大 生体システムビッグデータ解析オープンイノベーションラボラトリ」(CBBD-OIL)の開所式を行いました。
中鉢理事長の挨拶・設立趣旨説明の後、鎌田 薫 早稲田大学総長のご挨拶と経済産業省、文部科学省、学術界、産業界からのご来賓の方々よりそれぞれご祝辞を賜り、鎌田総長と中鉢理事長による調印式を行いました。
その後、産業界から3件のラボへのご期待のご講演の後、CBBD-OILの研究の方向性を、ラボ長に就任した早稲田大学 竹山 春子 教授及び副ラボ長に就任した産総研 油谷 幸代 企画主幹より説明しました。
当日は、ラボへの期待の大きさを示すように多くの関係者、そして多数の学生も出席し、盛況の内に開所式をとりおこなうことができました。

調印式の様子
|
|

記念撮影の様子
|