国立研究開発法人産業技術総合研究所(以下「産総研」という)プラットフォームフォトニクス研究センターのコン グアンウエイ 主任研究員らは日本電信電話株式会社と共同で、国立研究開発法人科学技術振興機構の支援のもと、電子回路ではなく、シリコン光集積回路を使った超低遅延かつ消費電力の少ないニューラルネットワーク演算技術を開発した。
この技術は、光集積回路を用いて機械学習の演算を行う技術である。解析すべき多次元データの電気信号は光集積回路のそれぞれ異なる入力ポートに入力されて光信号に変換され、さらに光集積回路に組み込まれた多数の光干渉計を通過する際に演算が行われる。そして、複数の出力ポートの光強度分布として演算結果が出力される。
この技術を用いることにより、電気回路を経ることなく、光集積回路のみによるニューラルネットワーク演算が実現した。このニューラルネットワーク演算では、パラメーターが固定された光集積回路に光を伝搬させるだけで演算が完了するため、デジタル電子回路のような逐次スイッチングが不要となり、電子回路の千分の1以下の遅延時間、かつ数十分の1の消費電力での演算が可能となる。また、光回路では電子回路の10倍以上の高速なクロックが適用できるため、単位時間あたりのデータ処理量も大きくできる。これらの特徴により、この技術はデジタル電子回路を補完するAIアクセラレーターへの応用が期待される。なお、この技術の詳細は2022年6月30日にSpringer Nature社刊行の「Nature Communications」で発表される。
本研究で考案した非線形写像型光ニューラルネットワーク演算回路、およびこれを用いた花弁形状によるアヤメの分類結果
高度にデジタルトランスフォーメーション化された社会では、データセンターからエッジコンピューティング、自動運転、そしてコンシューマーデバイスまですべての情報機器において、幅広いAI処理の適用が必要とされている。AI処理システムの規模は毎年10倍程度の爆発的な拡大を示しており、既に1000億パラメーターの超大規模システムも登場している。このようなAI処理システムは、大量のデジタル演算プロセッサにより構築されているが、デジタル演算は演算規模の拡大により消費電力や演算遅延の増加が著しい。例えば、512個のGPUで構成されるAI処理システムは12万ワット以上の電力が必要である。また、エッジコンピューティングやロボット制御、自動運転などでは小規模なシステムが必要であるが、画像認識などのAI処理においてミリ秒程度の遅延を発生し、高速レスポンスが求められるこれらの応用にむけた課題となっている。
そこで近年、デジタル演算によらない、低消費電力で低遅延、そして大量のデータの処理が可能な高スループットAIアクセラレーターの研究開発が進んでいるが、その一つの候補として、光集積回路を用いた光ニューラルネットワーク演算が注目されている。光ニューラルネットワーク演算は、パラメーターが固定された光集積回路に光を伝搬させるだけで演算が完了する。デジタル演算のようなデバイスのスイッチングが不要なため、消費電力が少なく、また光集積回路チップを光が伝搬する時間で演算が完了するため、演算遅延は極めて小さい。しかしながら、現在の光ニューラルネットワーク演算回路は、光を用いた非線形性応答デバイスの集積が困難なため、光信号を電気信号に変換し、電子回路によるデジタル演算でこれを実現するハイブリッドな構成となっていた。したがって、現在の光ニューラルネットワーク演算は、消費電力および演算遅延の両観点において、そのメリットが活かされていない。そこで、光集積回路だけでニューラルネットワーク演算を実現する技術の開発が望まれていた。また、光演算回路の学習は、コンピューターによる事前学習が主流であるが、自らの経験に基づいた自律的な学習にむけては、回路実機に対する直接学習が必要であった。
産総研では、次世代光集積回路技術であるシリコンフォトニクス技術の研究開発を進めてきた。シリコンフォトニクス技術は、シリコンエレクトロニクスの製造技術をベースとした光集積回路技術であり、微細加工性、集積性、経済性、そして省エネルギー性に優れ、近年の光集積回路の大規模化に必須の技術となっている。この技術を用いれば、光ニューラルネットワーク演算に必要な大規模光干渉計集積回路が実現可能である。さらに、シリコンフォトニクス技術により非線形応答を担うデバイスを実現できれば、光集積回路のみでのニューラルネットワーク演算が可能となる。そこで、我々は光干渉計デバイスの駆動電圧に対する非線形性を用いた演算方式をシリコン光集積回路に実装して、光集積回路のみによるニューラルネットワーク演算を世界で初めて実証した。
本研究開発は、国立研究開発法人科学技術振興機構のCREST「新たな光機能や光物性の発現・利活用を基軸とする次世代フォトニクスの基盤技術」(JPMJCR15N4)および「情報担体を活用した集積デバイス・システム」(JPMJCR21C3)の支援を受けて行った。
本研究では、光干渉計デバイスの駆動電圧に対する非線形性を用いるために、非線形写像型のニューラルネット演算方式を提案した。この演算方式では、データ入力部の光干渉計デバイスにより、解析すべきデータを高次元光複素振幅空間に非線形写像し、さらに多数の光干渉計から構成される光集積回路に光伝搬させることにより演算結果を得る。
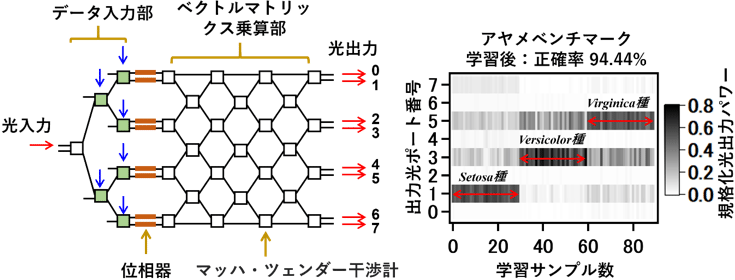
この演算方式を検証するための光集積回路をシリコンフォトニクス技術により製作した。図1(a)に製作した回路チップ、図1(b)に演算機能評価用に光ファイバーと電気配線を実装したモジュールの写真を示す。この回路は、シリコン導波路型マッハツェンダー光干渉計(MZI)および単体位相シフタを基本要素としたメッシュ構造となっている。MZIや単体位相シフタは導波路近傍に配置されたヒーターによる熱光学効果で動作する。この回路の動作原理について、分類演算を例に説明する。解析すべきデータは電気信号としてMZIに入力され、光信号に変換される。その際に、MZIの非線形応答により、入力データが高次元複素振幅空間に写像される。入力部を通過した光信号は、その後に控えている積和演算部を通過し、そこでの演算を経て、分類の境界を与える高次元平面が算出される。最終的な分類演算結果は、最大光パワーを示す出力ポートの位置で示される。この演算原理のイメージを図2に示す。
デバイスにある干渉計パラメーターの設定は、機械学習により実施された。学習には細菌採餌最適化アルゴリズム(BFO)、あるいは前方伝搬アルゴリズム(FP)を利用し、回路実機に対し直接に学習を実施した。回路実機による直接学習は、外部コンピューターによる事前学習とは異なり、自らの経験に基づいた自律的な学習習熟度の向上を可能とする技術であり、本研究の大きな成果の一つである。
この回路を用いた演算の例として、Iris flower classificationと呼ばれる分類演算用ベンチマークの結果を図3に示す。この分類演算ベンチマークはアヤメの花弁サイズからアヤメの種類を判別するものである。この図の横軸はサンプル番号を示すが、サンプル番号1~30、31~60、61~90にはそれぞれ異なる3種類のアヤメ(Setosa種、Versicolor種、Virginica種)を割り当てている。縦軸はこの回路の8個の出力ポートを示しており、1,3,5ポートをそれぞれ3種のアヤメに割り当てている(ポート1はSetosa種、ポート3はVersicolor種、ポート5はVirginica種)。分類結果は、最大光パワーを与えるポートが各アヤメ種に割り当てているポートと一致していれば正解となる(図3の右端の図参照)。学習前はサンプル番号と出力ポートの光パワーに相関はなく、分類はできていないが、90サンプルの学習後は、約94%の正答率で分類が可能となっている。さらに、学習に用いていない60サンプルに対しても分類を行い、約97%の正答率も得られている。
分類演算の処理時間は、光集積回路を光が通過する時間であるが、この場合は100ピコ秒以下であり、デジタル電子回路演算の約千分の一であった。また回路パラメーターの設定に要したヒーター電力は約360ミリワットであり、同じくデジタル電子回路演算の数十分の一であった。さらに、データ入力用干渉計を応答の遅いヒーター方式から数十GHzで動作可能なPN接合型高速シリコン光変調器に変更することにより、原理的には毎秒数100億回の高スループット演算も可能となる見込みである。
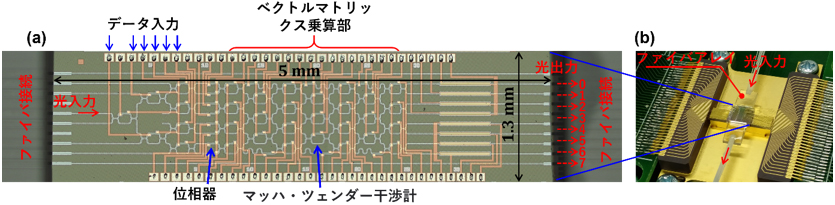
図1 (a) 製作したニューラルネットワーク演算用シリコン光集積回路 (b) 評価用実装モジュール
(図(a)はNature Communications誌に掲載された図面を和文に編集したもの)
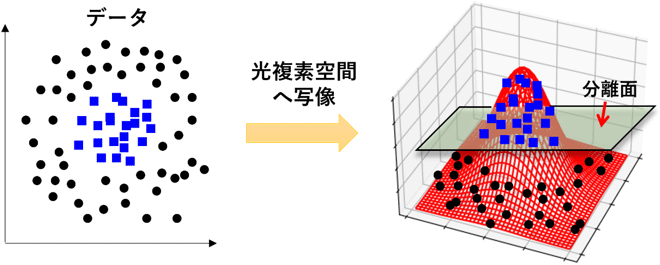
図2 非線形写像を用いた分類演算のイメージ図
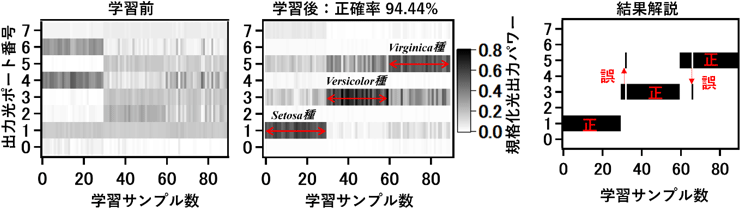
図3 アヤメの花弁形状による花種分類演算のベンチマーク結果。結果解説の図は学習後の結果を元に最大値を与えた出力ポートを示したものである。
(真ん中の図面はNature Communications誌に掲載された図面を和文に編集したもの)
今後は演算回路を大規模化し、より複雑な演算への適用性を確認していくとともに、高スループット化や学習機能の集積化にむけて、入力用高速光変調器や受光器の集積、デバイス駆動用、および学習制御用の電子回路の実装を進める予定である。また、今回提案した非線形写像型の演算方式をベースに、汎用データプリプロセッサや、再帰回路の付与による時間波形認識など、より幅広くかつ実用性の高い応用への適合性の確認を進める予定である。
掲載誌: Nature Communications
論文タイトル: On-chip bacterial foraging training in silicon photonic circuits for projection-enabled nonlinear classification
著者:Guangwei Cong, Noritsugu Yamamoto, Takashi Inoue, Yuriko Maegami, Morifumi Ohno, Shota Kita, Shu Namiki, and Koji Yamada